extract data from structured text files
Inspiration: Classic Shell Scripting Arnold Robbins and Nelson
A. F. Beebe, O'Reilly & Associates, 2005; Chapter 5 "Pipelines Can Do
Amazing Things"
"In this chapter we solve several relatively simple text processing jobs. What's interesting about all the examples here is that they are scripts build from simple pipelines: chains of one command hooked into another. Yet each one accomplishes a significant task."
----------
Sometimes we may wish to perform a text-to-text transformation, producing a
pretty-format report for human consumption from an existing storage-format data
source. In this example the passwd file is used from which to produce a desired
report. It demonstrates the power of pipelines, regular expressions, sed for
search-and-replace, and gawk for text field manipulation.
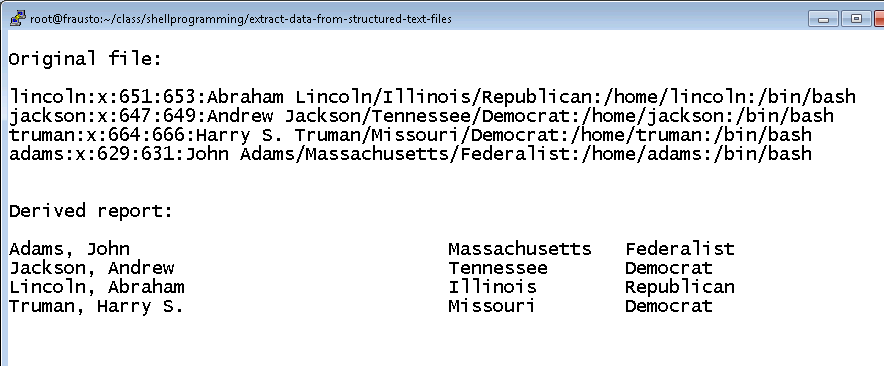
The passwd file has a well known, 7-field stucture. All but the 5th field have well defined content. That field is in effect a comment. Standard utilities don't use it for anything. You can put whatever you want in it. Imagine the passwd records for several U.S. presidents, in which the comment field is utilized to hold a president's name, home state, and party affiliation. From it, we wish to programmatically produce a report with certain content and format. Both the passwd file (raw material) and derived report (finished product) are shown below. (Obtain the abbreviated passwd file shown, holding four past U.S. presidents.)
How do we get from here to there? We will first produce a reduced starter file
that gets rid of the parts of the password file we don't want. Then from that,
we'll make 3 intermediate files corresponding to the 3 columns above: name,
state, political party. We can use gawk to select out
just the parts of the /etc/passwd records we do want, which are the 1st and 5th
fields. Test it manually on a single record by explicitly feeding gawk
just the one record:
echo truman:x:664:666:Harry S. Truman/Missouri/Democrat:/home/truman:/bin/bash | gawk -F: '{ print $1 ":" $5 }'
It extracts just the fields you specify. Or do it for all records, the whole file, by handing gawk the file on the command line. Please execute:
gawk -F: '{ print $1 ":" $5 }' ppasswd
(While you could manually type these commands, that's tedious and error prone. I suggest instead you copy them from this page and paste them into your shell. After copying to the clipboard a simple right click within your terminal window may suffice to paste, depending which terminal window program you are running. Paste at the prompt, hit enter, and you just executed the indicated command without risk of typo.)
This is the data and format we want at this stage:

Now we want to disaggregate this into 3 intermediate working files. :One will hold the person's
name, another his state, and finally the political party. Each will additionally
retain the user account name ("truman" as opposed to "Harry S.
Truman"), for use as a key field for associating the right records between
files. We will use pipelines to do it, liberally employing regular
expressions (in sed). First, you will do it on a manual, single-record basis.
Once you understand what is happening to each record, you will do it on a full
file-wide basis covering all records in the file.
We use President Truman's record as our sample. Carrying the above "truman:Harry S. Truman/Missouri/Democrat" format a stage further, execute:
echo truman:Harry S. Truman/Missouri/Democrat | sed 's=/.*=='
This turns truman:Harry S. Truman/Missouri/Democrat into truman:Harry S. Truman
and then, additively (you could use command history to recover the last command, then pipe-extend it):
echo truman:Harry S. Truman/Missouri/Democrat | sed 's=/.*==' | sed -e 's=^\([^:]*\):\(.*\) \([^ ]*\)=\1:\3, \2='
This turns it further into last, first middle form as truman:Truman, Harry S.
That's the form we want for the first of our 3 intermediate files. Detailed analysis of this regular expression is depicted below, in the section titled OPERATION 1.
The format we'll want for the second file follows this pattern:
echo truman:Harry S. Truman/Missouri/Democrat | sed -e 's=^\([^:]*\):[^/]*/\([^/]*\)/.*$=\1:\2='
It turns truman:Harry S. Truman/Missouri/Democrat into truman:Missouri
This regular expression is annotated below in the section titled OPERATION 2.
And for the third file's format:
echo truman:Harry S. Truman/Missouri/Democrat | sed -e 's=^\([^:]*\):[^/]*/[^/]*/\([^/]*\)$=\1:\2='
which turns truman:Harry S. Truman/Missouri/Democrat into truman:Democrat
The regular expression is detailed in the section below titled OPERATION 3.
Now make whole files, using the same regular expressions you just tested:
gawk -F: '{ print $1 ":" $5 }' ppasswd > USER
sed 's=/.*==' USER | sed -e 's=^\([^:]*\):\(.*\) \([^ ]*\)=\1:\3, \2=' | sort >
PERSON
sed -e 's=^\([^:]*\):[^/]*/\([^/]*\)/.*$=\1:\2=' USER | sort > STATE
sed -e 's=^\([^:]*\):[^/]*/[^/]*/\([^/]*\)$=\1:\2=' USER | sort > PARTY
With these intermediate files prepared, holding the pieces of data desired
for the final report in the desired form, let's join them to generate that
report. (Note above that we made sure to sort our keyed intermediate files to
meet the requirements for join-ing them now.) I suggest you do it in stages to
reveal what is going on:
join -t: PERSON STATE
join -t: PERSON STATE | join -t: - PARTY
join -t: PERSON STATE | join -t: - PARTY | cut -d: -f 2-
join -t: PERSON STATE | join -t: - PARTY | cut -d: -f 2- | sort -t: -k1,1 -k2,2 -k3,3
join -t: PERSON STATE | join -t: - PARTY | cut -d: -f 2- | sort -t: -k1,1 -k2,2 -k3,3 | awk -F: '{ printf("%-39s\t%s\t%s\n", $1, $2, $3) }'
There is the report. Isn't it pretty?
Here is a script that packages all this for programatic execution.
----------
OPERATION 1 - basis for producing the intermediate file PERSON from the
file USER
Objective: account name, colon, person's name in form last, comma, first and middle
sed 's=/.*=='
applied to:
truman:Harry S. Truman/Missouri/Democrat
| COLOR | MEANING | CONTENT | Also known as |
| green | a slash followed by a run (*) of any characters (.) | /Missouri/Democrat |
output expression is input with replacement (of matched expression, with
nothing)
so in this case
input truman:Harry S. Truman/Missouri/Democrat
yields
output truman:Harry S. Truman
then:
sed -e 's=^\([^:]*\):\(.*\) \([^ ]*\)=\1:\3, \2='
applied to:
truman:Harry S. Truman
| COLOR | MEANING | CONTENT | Also known as |
| grey | beginning of line | ||
| green | a run ( * ) of characters that are not colons ( [^:] ) | truman | \1 |
| red | a colon | : | |
| turquoiise | a run ( * ) of any characters ( . ) | Harry S. | \2 |
| uncolored | a space | the space between . and T | |
| purple | a run ( * ) of characters that are not spaces ( [^ ] ) | Truman | \3 |
output expression is \1:\3, \2
so in this case
input truman:Harry S. Truman
yields
output truman:Truman, Harry S.
----------
OPERATION 2 - basis for producing the intermediate file STATE from the
file USER
Objective: account name, colon, person's state
sed -e 's=^\([^:]*\):[^/]*/\([^/]*\)/.*$=\1:\2='
applied to:
truman:Harry S. Truman/Missouri/Democrat
| COLOR | MEANING | CONTENT | Also known as |
| grey | beginning of line | ||
| green | a run ( * ) of characters that are not colons ( [^:] ) | truman | \1 |
| red | a colon ( : ) followed by a run ( * ) of characters that are not slashes ( [^/] ) followed by a slash | :Harry S. Truman/ | |
| turquoiise | a run ( * ) of characters that are not slashes ( [^/] ) | Missouri | \2 |
| purple | a slash ( / ) followed by a run ( * ) of any characters ( . ) at the end of the line ( $ ) | /Democrat |
output expression is \1:\2
so in this case
input truman:Harry S. Truman/Missouri/Democrat
yields
output truman:Missouri
----------
OPERATION 3 - basis for producing the intermediate file PARTY file from
the file USER
Objective: account name, colon, person's political party
sed -e 's=^\([^:]*\):[^/]*/[^/]*/\([^/]*\)$=\1:\2='
applied to:
truman:Harry S. Truman/Missouri/Democrat
| COLOR | MEANING | CONTENT | Also known as |
| grey | beginning of line | ||
| green | a run ( * ) of characters that are not colons ( [^:] ) | truman | \1 |
| red | a colon ( : ) followed by a run ( * ) of characters that are not slashes ( [^/] ) followed by a slash ( / ) followed by another run of characters that are not slashes followed by another slash | :Harry S. Truman/Missouri/ | |
| turquoiise | a run ( * ) of characters that are not slashes ( [^/] ) at the end of the line ( $ ) | Democrat | \2 |
output expression is \1:\2
so in this case
input truman:Harry S. Truman/Missouri/Democrat
yields
output truman:Democrat