
Client-server computing is supported by an underlying mechanism called "sockets." It is a generalized form of inter-process communication (IPC). IPC is a feature of most operating systems that lets two processes running in the computer communicate with each other. Sockets extend that same capability to pairs of processes that don't happen to be running in the same computer. Two distinct and separate computers, provided they're connected by a network, will do. So sockets offer not just inter-process, but inter-machine inter-process communication.
Clients and Servers as Network Programs
Client programs and server programs achieve their ability to reach one another by tying in to the network software already running in their computers. As such, client and server programs become a software "layer" in the overall network scheme. They are applications, sitting above the lower layers that are the networking infrastructure for the computer, at the disposal of all who need to reach other machines. Client and server programs do this by employing the socket API programming interface.
An API (application programming interface) is a prescribed methodology for accessing some sort of service that has already been written. That way the programmer doesn't reinvent the wheel. The API usually amounts to some step-by-step rules for calling a certain set of functions. In this case, the programmer doesn't need to include code for conducting the networking details. That code already exists. He just needs to learn how to call it. The socket API is how he calls it. It originated as part of BSD Unix at the University of California and is a de facto standard.
Sockets and files are used similarly
Socket programming parallels Unix file I/O programming, with which many are familiar. This makes sense since a file is a source or destination to or from which to move data, and so are sockets. But sockets move the data along beyond themselves to another socket on another machine, ultimately to a process running there.
File I/O follows a sort of API of its own. The set of functions involved include fopen( ), fread( ), fwrite( ), fclose( ) or similar. The main idea is that you first identify a file, then direct your reads and writes to it. The normal way to identify a file is using its filename. After all, enabling that is the central purpose of filesystems. However, from the operating system's point of view, using filenames and repeatedly resolving them to lower-level references each time a program mentions a file becomes tedious and inefficient. Within programs therefore, the filename is given only once at the outset, to the fopen( ) function. fopen's purpose is to provide a replacement identifier that is more compact and efficient. That identifier is used by the program thereafter whenever interaction with the file is desired. The replacement identifier is called a file handle or file descriptor. A variable is set up to receive and contain it. A simplified sequence for reading and writing something uses this paradigm like this:
declare variable fd
fd = fopen(<name of file>)
fread( fd, <where to put what you read> )
fwrite( fd, <the stuff you want written> )
fclose( fd )
Note that beyond the second line, the program continues referring to the file but always with the file descriptor obtained in the second line, never again by the file's name. Exactly how the file functions operate beneath the covers, we don't know. But we don't need to, they just work.
Sockets work similarly. A program that wants to engage in talk with a program not running on the same computer first gets a "socket" created and obtains a descriptor for it. Then it uses the descriptor in other function calls to put that socket to use. Along the way, there are some extra operations, and corresponding function calls, having to do with hooking up with the right remote process on the right remote computer. Once that's done however, there are socket read, write, and close functions just as for files.
The socket API
The set of functions comprising the API include primarily:
socket( )
bind( )
connect( )
listen( ) and accept( )
read( ), recv( ), recvfrom( ), or recvmsg( )
write( ), send( ), sendto( ), or sendmsg( )
close( )
bind( ) is used particularly by server programs, and connect( ) by client programs. The others are used by both.
bind( ) applies a "name" to an existing socket, so that it can be referred to. The essence of this "name" or identifier, is an IP-address-and-port-number pair. connect( ) searches out an already named (or "already bind'ed") program out on the network, by name. So calls to bind( ) supply, as parameters, information that tells which socket and what name. And calls to connect( ) supply a local socket, and the name of a remote socket to search for, locate, and connect to.
Once a server program has created a socket and named it with bind( ) giving it an IP address and port number, should any program anywhere on the network give that same name to the connect( ) function, that program will find our server program and they will link up. The server program uses the accept( ) function to react to the client's connect( ). So the accept( ) must be called before the connect( ) is issued. Once all this connecting and accepting is done, both sides can freely use read/write or recv/send to get stuff shipped to each other.
Essential models for client and server programs
All this can support a layer of software where one side can design various forms of request, and the other various forms of response. Numerous types of client-server "languages" for specific pairs abound, having been designed to take advantage of this platform to achieve a variety of purposes. They are called protocols. Examples are ftp (the purpose being transfer of files), telnet (the purpose being remote extension of login service), http (the purpose being the supply of text which can lead to request for other text further linked to it), smtp (the purpose being the acceptance and dispatch of messages in a system functioning as does traditional mail), and so on. Sockets are the basis of all these familiar network functions.
The model, stripped-down client socket program looks something like this:
my_sd = socket( )
his_sd = connect( my_sd, <presumed adderss of some server> )
send( his_sd, <the stuff you want sent> )
recv( his_sd, <where to put what you receive> )
close( my_sd )
whereas the corresponding, stripped-down server looks like:
my_sd = socket( )
bind( my_sd, <local address, mainly a port number> )
listen( my_sd )
start loop
his_sd = accept( my_sd, <empty address to be filled in
with his incoming info> )
recv( his_sd, <where to put what you receive> )
send( his_sd, <the stuff you want sent> )
close( my_sd )
end loop
This is very stripped-down and rudimentary, but faithful to the open-connect-read-write-close paradigm client and server programs actually use. Real programs, where the above examples show a single send/recv or recv/send pair, actually do a lot of more elaborate, conditional, and extensive operations with sends and receives freely embedded. But the fundamental model is as depicted. Here's another author's representation:
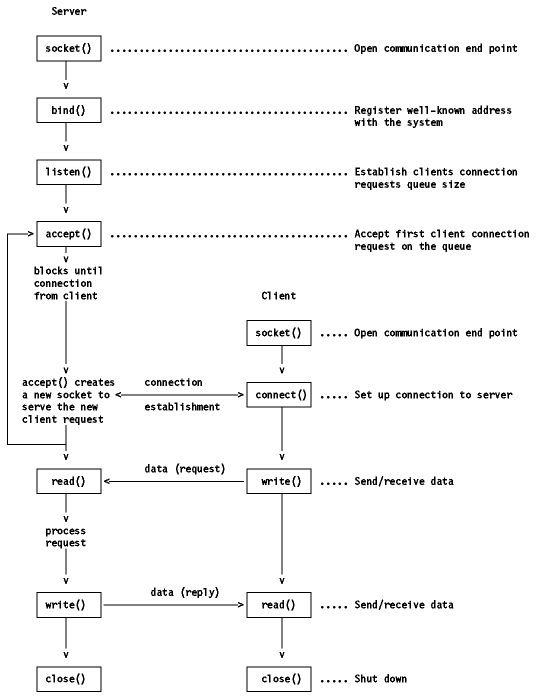
Note the client shown sends first, then receives, while the server
receives first, then sends. This reflects the natural roles of the two. Clients
are askers; servers are answerers. Clients initiate by making a request, so the
client at first sends and the server receives. Then, the server responds. In the volley between them, at the second step, it is the server who sends
and the client who receives. The server would typically contain code between its
recv and send. The received material from the client would be a request. The
code between recv and send would be the server's reaction to fulfill it. That
code would generate a response intended for the client. Which is what the send
would send.
Here are some model pairs of client-server programs:
- letter-upgrader server
- letter-upgrader's client
- upper-echoback
server
- client for echo-back server
- web
(file-send) server
- client for file-send
server
They all follow the above outline/model but do different things in
interacting with each other.
References
There are treatments of this subject in:
Computer Networks and Internets, Douglas Comer, Prentice Hall, 2001 Chapter 27, "The Socket Interface," and
Beginning Linux Progamming, Neil Matthew and Richard Stones, Wrox Press, 1996, Chapter 13, "Sockets."
Linux Programming Unleashed, Wall, Watson, and Whitis, SAMS, 1999, Chapter 19, "TCP/IP and Socket Programming"
I particularly like the explanations in the first two references, and the examples in the third.
This appears to be a not bad tutorial that uses the analogy of the telephone to explain sockets. And here's a FAQ with more than you bargained for.