Exercise: the client/server model
different kinds of sockets
The client-sever model
The client-server model joins programs in pairs so that they may communicate. The idea is that sometimes one program would benefit if another would give it something, or do some work for it. The model provides a mechanism for asking.
The worker program is called the "server," the beneficiary program the "client," and the request mechanism the "socket programming interface" or socket API. The model says nothing about what the server should give the client or do for it. It only creates the framework enabling delivery-- of the request from client to server, and of fulfillment (whatever was requested) from server to client. Within this framework there are different kinds of "delivery" each with its own variant of API usage and corresponding protocol. UDP is one way to deliver something, TCP is another. Each has its own variant of coding the API calls, which is what selects and triggers them.
I have often used a pair of demonstration program for this in a previous course, wherein a minimalist client and server trade a couple of letters from the alphabet. The client sends any chosen letter to the server, which increments it to the next letter and sends that back. The point of the programs is to highlight the sending and receiving, and the code that makes it happen. We don't care at all what gets sent here. So the demonstration programs are stripped down to send and receive as little as possible in order to highlight just the send mechanism, the socket API.
My pair of programs does the job using tcp over ip. Now, we are interested in extending the example to one that use udp, rather than tcp, over ipv4. And another that uses tcp over ipv6, rather than ipv4.
the exercise to perform
You will do this exercise in a single linux machine, running both client and server in that machine.
|
Note: there is no conflict in that. When two programs interact as client and server, the requirement is the the client must run on a machine, the server must also run on a machine, and they must interact through the network stack software. Your machine is a machine so satisfies both client's and servers's locus requirement. And the stack's loopback interface provides boomerang from/to connectivity between a machine and itself. |
Later this exercise or parts of it could be moved onto a machine pair. If you are using VirtualBox the CLIENT machine from the "sniffing" exercise is a suitable platform.
Log in to the machine as student, launch the graphical desktop ("startx" command), from which launch a terminal window (icon under "Activities" menu), in which become root ("sudo su -" command). Make a subdirectory within your home directory:
cd
mkdir clientserver
cd clientserver
In that directory obtain file programs-my-adapted-letter-upgraders.tar. It is a tar file, simliar to a zip file. Deploy the several files it contains:
tar -xzvf programs-my-adapted-letter-upgraders.tar.gz
A client program that wishes to contact its server needs to know an IP address of the machine where the server runs, and the port number by which the server is identified within its machine. These programs hard code that information. As coded, the clients use the self-referential IP address of the machine where they themselves run (127.0.0.1 for ipv4 and ::1 for ipv6). That means you have to run the server on the same machine as the client. And for port number they all hardcode 2910 (arbitrarily). Later in the client, for experimentation, you could edit the IP address (and move the server to it) and/or the port number (and conform the server code to match it). But for now we will run both client and server together on the same machine.
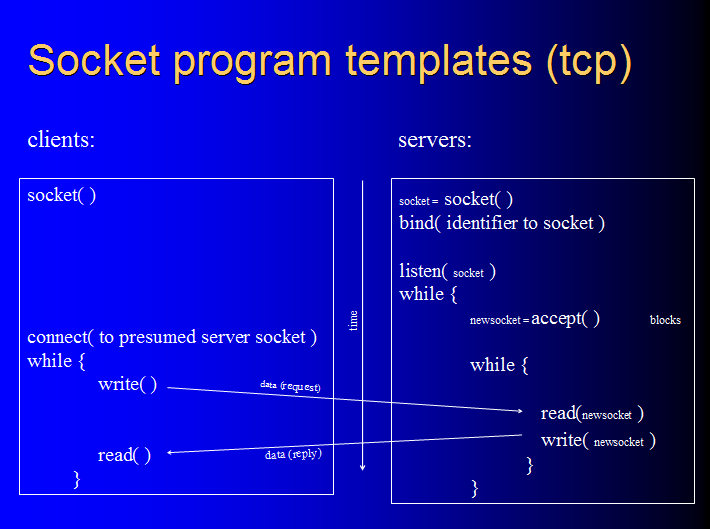
tcp clients and servers have a signature pattern of socket API call utilization, in terms of which ones they call and in which order.. Here are what tcp clients and servers look like:
Observe the pattern in our baseline sample programs:
cat -n client3.c
cat -n server3.c
Observe that, for example, the client has "socket( )" in line 22 and "connect( )" in line 33, while the server has "socket( )", "bind( )" and "listen( )" in lines 17, 23, and 25 respectively. Locate in the code the other socket calls shown in the templates, and that their placement corresponds to the templates. These tcp network programs, and network programs generally, follow the pattern. That's what a tcp network program is.
We can examine these cases:
- baseline - tcp over ipv4
- variant - udp over ipv4
- variant - tcp over ipv6
Exercise the baseline client/server pair
Compile the baseline client and server:
gcc client3.c -o client3
gcc server3.c -o server3
Run the baseline server:
./server3 &
Press the enter key a couple times. The server is running in the background ("&" did that). Though not prominent it's up, running, and ready for contact from a client. So:
./client3
The letter that client3.c is hard coded to send is R, so the server returns S and the client says so on screen.
killall server3
Let's capture these this interaction in Wireshark. Launch Wireshark. Start capturing on the loopback interface, lo. (You won't have distracting background traffic on quiescent interface lo, so no worry about filtering.) In one stroke-- launch the server, run the client, and take the server down:
(./server3 &); sleep 1; ./client3
In Wireshark stop the capture and save it to file "letter-upgrader-tcp-over-ip4.cap". Then stop the server:
killall server3-ip6
Exercise one of the alternative client/server pairs: UDP
udp clients and servers have a signature pattern of socket API call utilization, different from tcp's. Here are what udp clients and servers look like:
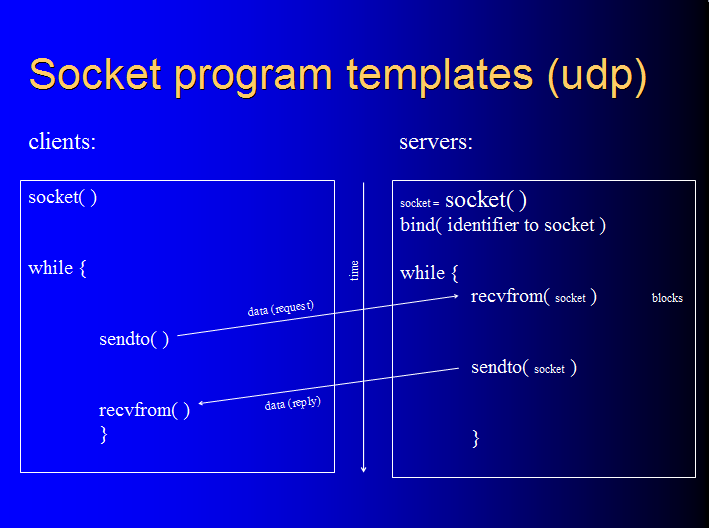
Observe the pattern in our baseline sample programs:
cat -n client3-udp.c
cat -n server3-udp.c
Observe that, for example, the client has "socket( )" in line 22, "sendto( )" in line 42, and "recvfrom( )" in line 43. And the server has "socket( )" in line 17, "bind( )" in line 23, "recvfrom( )" in line 37, and "sendto( )" in line 39. These udp network programs, and udp network programs generally, follow the pattern.
Compile the udp variant's client and server:
gcc client3-udp.c -o client3-udp
gcc server3-udp.c -o server3-udp
Relative to the baseline these change the transport protocol. Without changing the network protocol, ipv4, they use udp instead of tcp.
Run the udp version, just as you did with the tcp version already:
./server3-udp &
./client3-udp
killall server3-udp
The experience is identical. What was delivered and returned is the same in both cases.
That's the thing we don't care about. R and S do not interest us. What we do care about is the send mechanism, the socket API as used (differently) within the pair of programs. So we will need to do some examination and comparison of code. What is different about that, and the underlying actions it represents?
To investigate, put the source code of the two clients side by side:
vim -c "syntax off" -d client3.c client3-udp.c
This is the vim editor's diff mode, convenient for comparing similar texts. Similar lines that differ have colored background, and the embedded differences within them are highlighted making differences easy to spot. (To show line numbers press : (colon) then type "set number" and hit enter. Study the screenshot, shown below. To move cursor back and forth between documents press ctrl-W twice.) Study the screenshot. It should look like this:
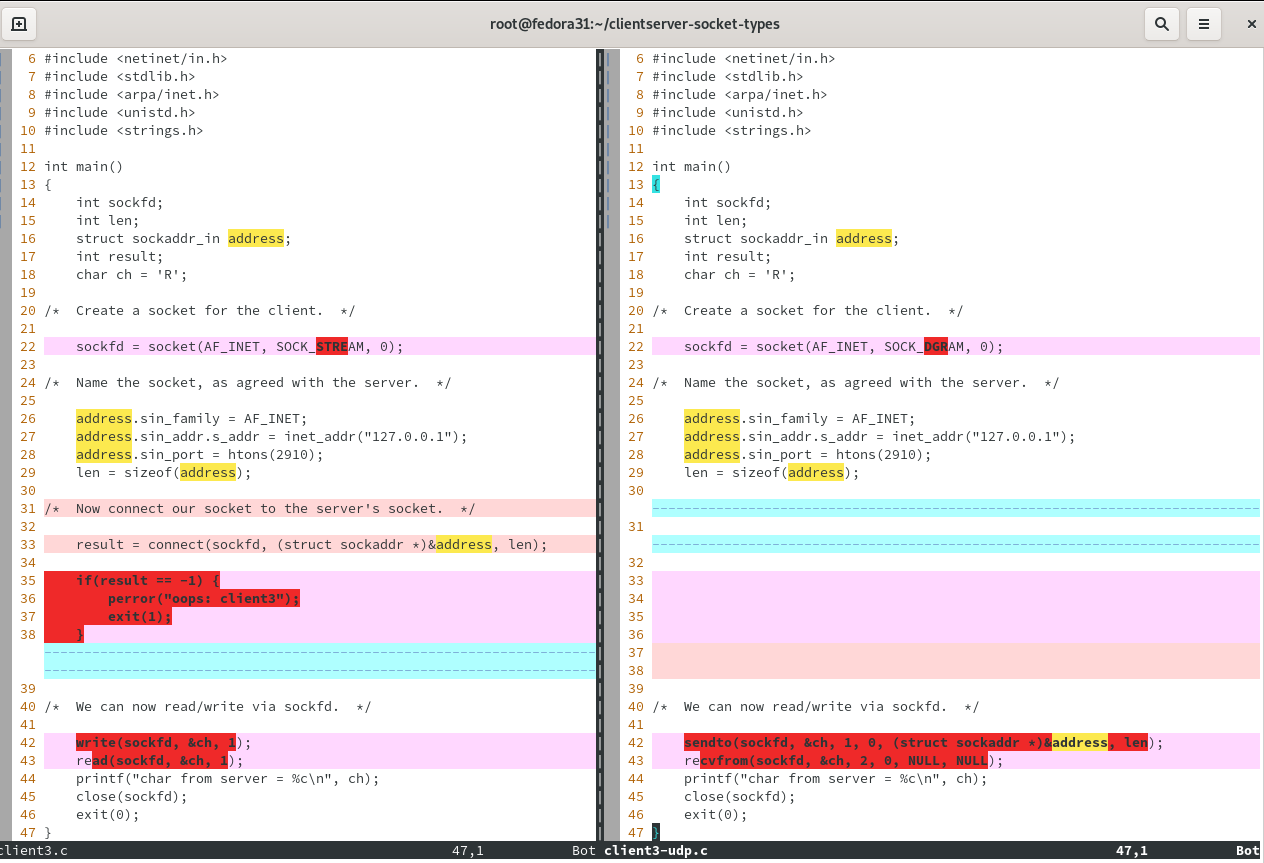
What are the differences and what to they mean?
Line 22 - there's a socket call argument SOCK_DGRAM for udp in place of tcp's SOCK_STREAM. You get a different kind of socket, depending.
Line 33 - there's nothing in the udp version, where there was a connect( ) call in the tcp version. This reflects the fact that udp dispenses with the notion of a connection, hence also with calling a function to produce one.
Lines 42-43 - in both cases, reflecting the raison-d'etre and soul of client-server computing, the client sends something and the server receives it; then the server sends something and the client receives it. But the differences are 1) the function calls employed, and 2) the number of arguments. udp needs to operate differently than tcp when sending and receiving. So there are dedicated functions sendto( ) and recvfrom( ) for udp to use, while tcp uses write( ) and read( ). Here, both tcp's write( ) and udp's sendto( ) ask the transport protocol to send one character, supplied at a particular memory address, into/through a particular pre-constructed socket. udp goes a step further, specifying where to send it in the form of a structure (here named "address") that contains the IP and port of a destination. tcp didn't bother with that. Why? It reflects the aforementioned lack of a "connection" in udp. tcp associated the socket (sockfd) with a particular IP/port in line 33's connect( ) call. By telling write( ) which port to use, the destination is unambiguous in tcp. udp by contrast never associates the socket it creates with any particular destination. The same socket can be used to send stuff to different ones. Therefore, the ambiguity must be resolved in each and every sendto( ) call by dictating an IP/port destination at call-time. tcp did it already at connect-time.
Quit from both open files by typing colon-q-a-enter (q-a means quit all).
Now put the source code of the two servers side by side:
vim -c "syntax off" -d server3.c server3-udp.c
(To show line numbers press : (colon) then type "set number" and hit enter. Study the screenshot, shown below. To move cursor back and forth between documents press ctrl-W twice.)
What are the differences and what to they mean?
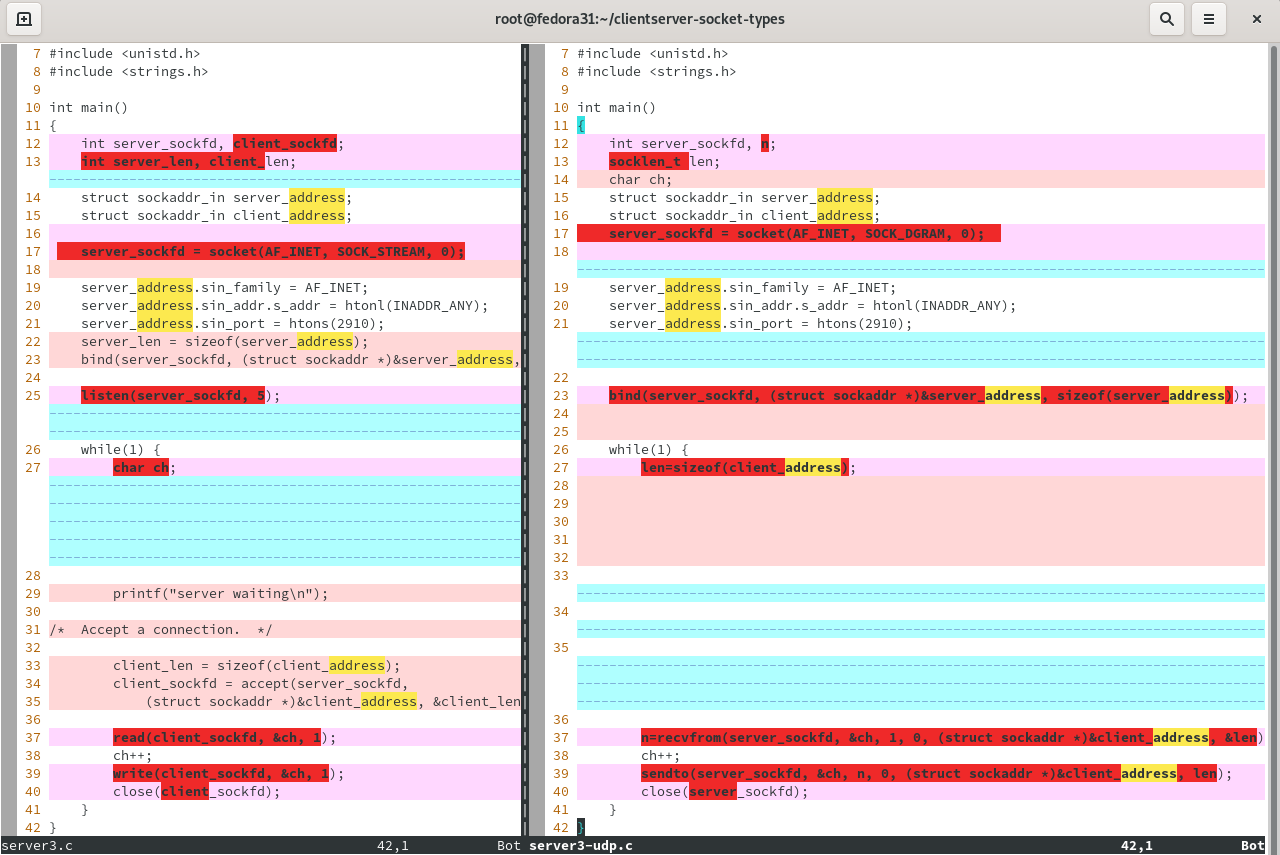
Line 25 and lines 33-35 - these contain listen( ) and accept( ) for tcp, which are missing for udp. These calls have to do with connections, and udp has none.
Lines 37 and 39 - these do the receiving and sending. In tcp they are independent of each other. In udp it's a little different.
udp maintains only one socket to serve more than one possible client. So data coming in from different clients gets comingled in a single buffer. If something coming in from a client needs a reply, or multiple clients send things ("requests") in need of replies, it's important to send the right replies to the right requestors. That requestor needs to be identified in each sendto( ) call, separately, as a destination for the reply to get sent to. This is done through the structure called "client_address" in our udp server. It contains the identity of the requestor, supplied by the requestor. It is then ploughed back into the ensuing sendto( ) on the other, replying machine so that the reply manufactured there can go to the right party. It could be compared to a postal "backing address."
With udp no pre-connect is performed (no 3-way handshake). Consequently, recvfrom/sendto can't be like read/write. tcp's accept( ) returns a socket descriptor (when client connects and server accepts). This is additional to the socket the server originally created for itself with socket( ). It embodies the "network identity" of who is calling (ie, the client). Each connecting client gets his own. So read/write just reference the client's descriptor in order to talk to the right guy. But udp's recvfrom needs to be told who it is hearing from each time something comes in since, unlike read, it isn't connected to just one client but to any-and-all who may call. It then has to hand that information off into sendto so that sendto knows to whom to send. The Fourouzan textbook (TCP/IP Protocol Suite p552) states, "Since UDP is a connectionless protocol, one of the arguments [to recvfrom or sendto] defines the remote socket address" which is unnecessary for read/write. The Stevens/Fenner/Rudoff book (UNIX Network Programming p240ff) indicates recvfrom gets a client_address structure (which it fills in, see man recvfrom) that is then passed to sendto, which tells the latter to whom to reply. This is needed because there is only 1 receive buffer shared among any and all clients. udp programs block on recvfrom waiting until there is incoming data, whereas tcp programs block on accept waiting until there is an incoming connection request.
Let's capture the udp interaction in Wireshark. Launch Wireshark, or restart a new capture (discard the old) if it's already running. Start capturing on the loopback interface, lo. (You won't have distracting background traffic on quiescent interface lo, so no worry about filtering.) In one stroke-- launch the server, run the client, and take the server down:
(./server3-udp &); sleep 1; ./client3-udp
In Wireshark stop the capture and save it to file "letter-upgrader-udp-over-ip4.cap". Then stop the server:
killall server3
Exercise one of the alternative client/server pairs:
ipv6
Compile the ipv6 variant's client and server:
gcc client3-ip6.c -o client3-ip6
gcc server3-ip6.c -o server3-ip6
Relative to the baseline these change the network protocol. Without changing the transport protocol, tcp, they use ipv6 instead of ipv4.
Run the ipv6 version, just as you did the ipv4 version already:
./server3-ip6 &
./client3-ip6
killall server3-ip6
Again the experience is identical. We got the same result, same end. But, transparently, different means.
That's the thing we don't care about. R and S do not interest us. What we do care about is the send mechanism, the socket API as used (differently) within the pair of programs. So we will need to do some code examination and comparison. What is different about how the socket API was coded, and what differences in implementation and behavior does the difference represent?
To investigate, put the souce code of the two clients side by side:
vim -c "syntax off" -d client3.c client3-ip6.c
(To show line numbers press : (colon) then type "set number" and hit enter. Study the screenshot, shown below. To move cursor back and forth between documents press ctrl-W twice.)
Your screen should look like this:
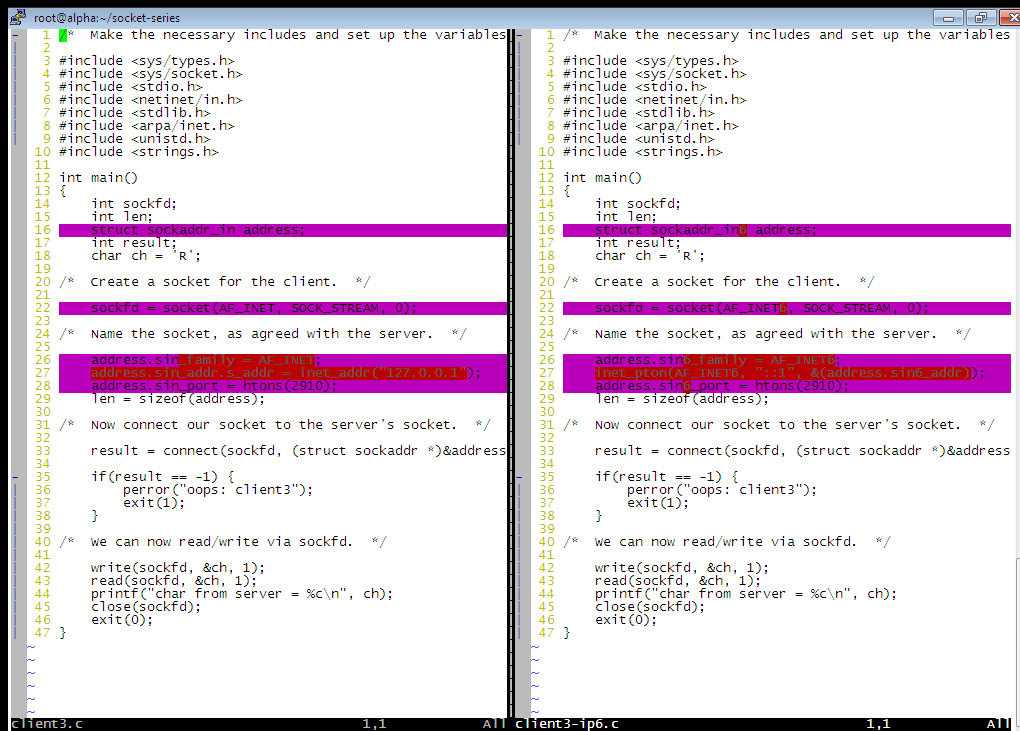
What are the differences and what to they mean?
Line 16 - both ipv4 and ipv6 create a data structure called a socket, and in so doing create and utilize a data structure called an address. The "structure" of both, as you can easily imagine, will differ between the older ipv4 and the re-engineered one, ipv6. Thus, when we define and name a C structure variable "address" in both line 16's, we ask that it be an ipv4 style structure in the ipv4 program, and an ipv6 type structure in the ipv6 one.
Line 22 - similarly we ask for a different kind of socket (AF_INET6 "address family" argument) for ipv6 than we do (AF_INET argument) for ipv4.
Lines 26-28 - these put values in the elements of the socket "address" data structures. Lines 26 and 28 do it pretty much the same way. address structures contain an element that names the address family they belong to, and line 26 sets it to ipv4 or ipv6 family as appropriate. The socket address also has an element for a port number ( socket address = IP address + port number ), and the line 28's handle that. Both line 27's are concerned with setting the same thing, inserting the IP address in binary form into the socket address structure. In both cases we supply the address expressed in the human convention ( e.g., 127.0.0.1 or ::1 ) but this needs to end up being a 32-bit or 128-bit binary number. inet_addr( ) does it in the ipv6 client, and that gets assigned into the socket address structure. In the ipv6 version, we give that structure as argument to a function (pton, expressing human Presentation TO binary Numeric conversion). The function then inserts the right 128 bits into its argument. Either method, the binary address gets put in the right place.
The rest of the client is unchanged.
Quit from both open files by typing colon-q-a-enter.
Now put the source code of the two servers side by side:
vim -c "syntax off" -d server3.c server3-ip6.c
Study the screenshot, shown below. What are the differences and what to they mean?
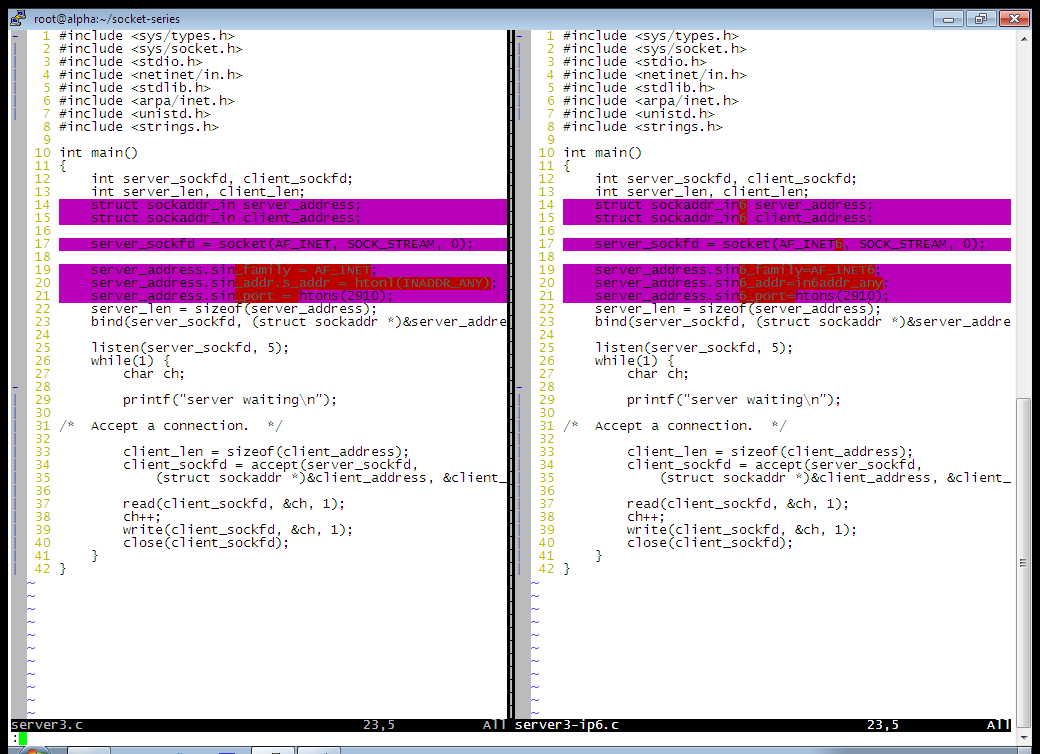
The differences between these are minor, mainly specifying "6 style"
as opposed to "4 style" where the syntax rules require the
"style" to be identified.
Let's capture these this interaction in Wireshark. Launch Wireshark, or restart a new capture (discard the old) if it's already running. Start capturing on the loopback interface, lo. (You won't have distracting background traffic on quiescent interface lo, so no worry about filtering.) In one stroke-- launch the server, run the client, and take the server down:
(./server3-ip6 &); sleep 1; ./client3-ip6
Stop the capture and save it to file "letter-upgrader-tcp-over-ip6.cap". Then stop the server:
killall server3-ip6
Above we compared and contrasted the source code of our variants. You can now
compare their packet traces, given that you captured the variants' behaviors
in
letter-upgrader-tcp-over-ip4.cap
letter-upgrader-udp-over-ip4.cap
letter-upgrader-tcp-over-ip6.cap
Study and compare the captures. Run the Wireshark feature "Follow TCP [or UDP] Stream" in each. Examine the ipv6 headers.
Discuss similarities and differences among the programs with classmates and instructor.
What to turn in
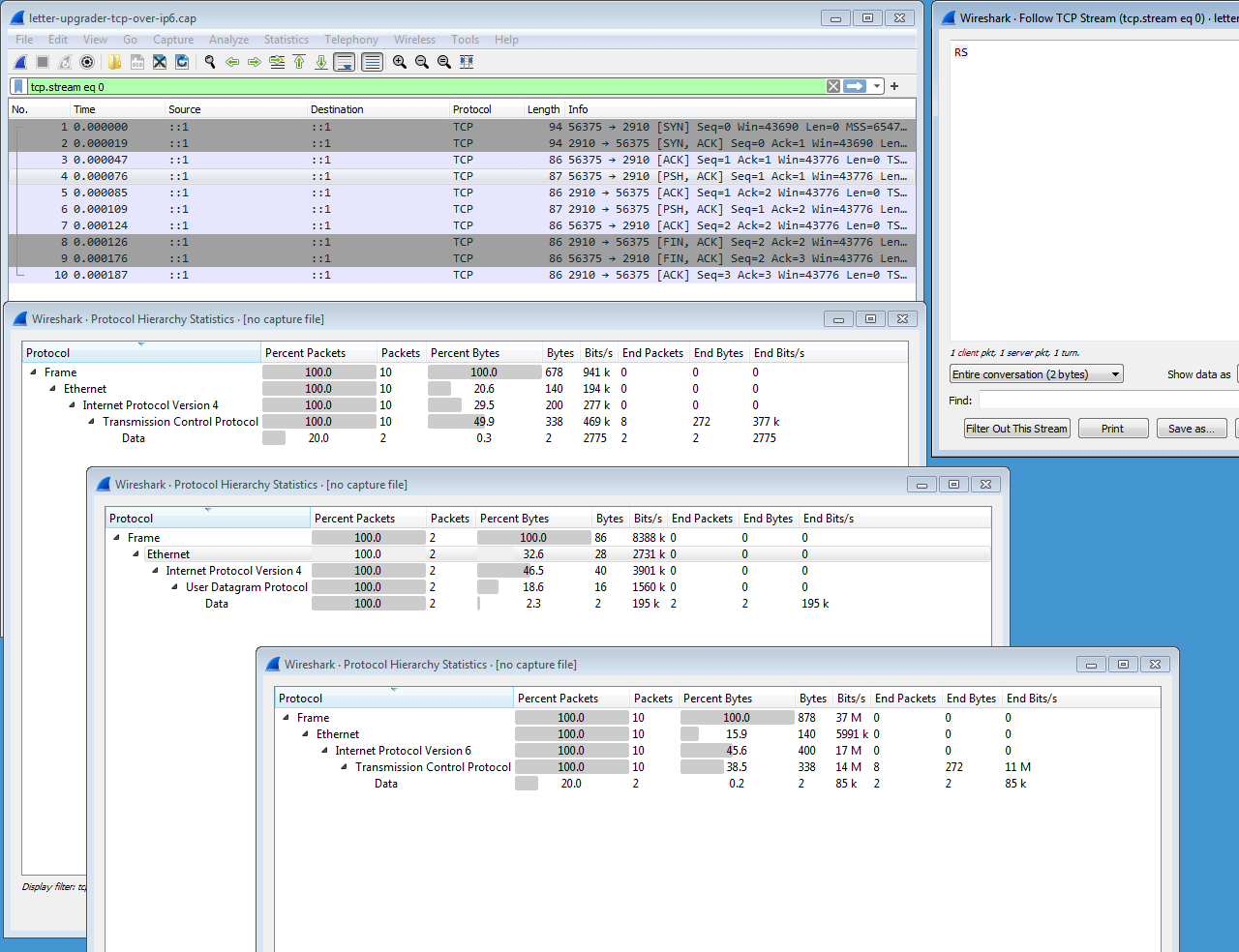
From your three capture files create a screenshot like this.
To do so, open letter-upgrader-tcp-over-ipv6.cap in Wireshark. Position it in at the top left of the screenshot. On top of that and below its packet list panel cascade three protocol hierarchy report windows, one for each capture. To obtain them open each capture file in succession and, while open, produce the report from the "Protocol Hierarchy" suboption on the "Statistics" drop-down menu. Position the cascaded reports in the vertical order shown, tcp/ipv4 above udp/ipv4 above tcp/ipv6. Finally, put a window in the upper right that follows the tcp stream from the ipv6 capture (in the ipv6 capture window you've opened at the top of the screen, right click on any frame and choose "Follow," then "TCP Stream."
Save your screenshot in a file named socket-types.jpg (or .png).
{kind=link}