Exercise: the client/server model
iterative vs concurrent servers
The client-sever model
The client-server model joins programs in pairs so that they may communicate. The idea is that sometimes one program would benefit if another would give it something, or do some work for it. The model provides a mechanism for asking.
The worker program is called the "server," the beneficiary program the "client," and the request mechanism the "socket programming interface" or socket API. The model says nothing about what the server should give the client or do for it. It only creates the framework enabling delivery-- of the request from client to server, and of fulfillment (whatever was requested) from server to client. Within this framework there are different kinds of "delivery" each with its own variant of API usage and corresponding protocol. UDP is one way to deliver something, TCP is another. Each has its own variant of coding the API calls, which is what selects and triggers them.
I have often used a pair of demonstration program for this in a previous course, wherein a minimalist client and server trade a couple of letters from the alphabet. The client sends any chosen letter to the server, which increments it to the next letter and sends that back. The point of the programs is to highlight the sending and receiving, and the code that makes it happen. We don't care at all what gets sent here. So the demonstration programs are stripped down to send and receive as little as possible in order to highlight just the send mechanism, the socket API.
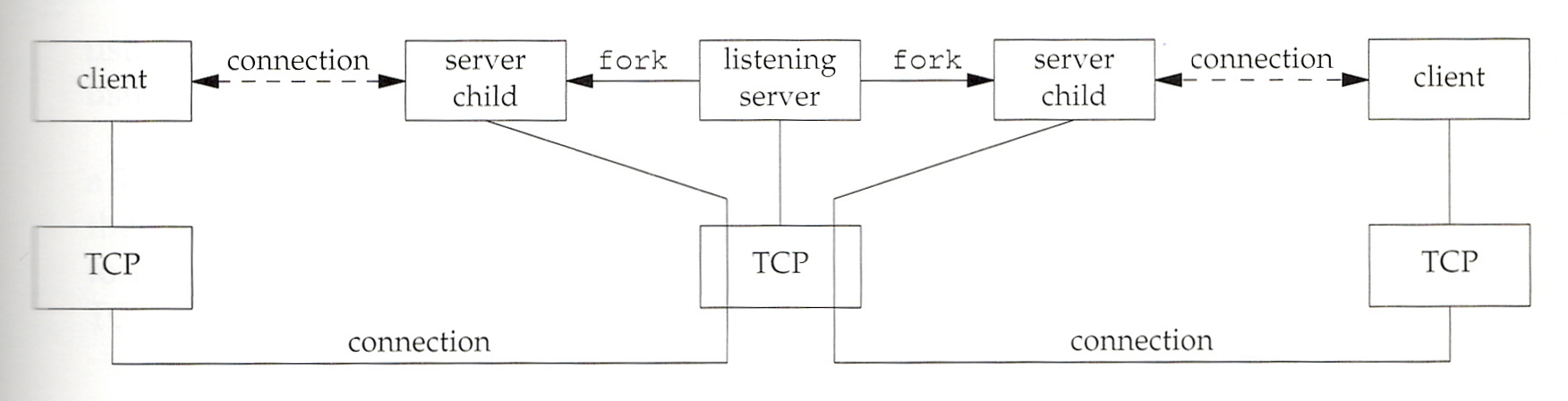
The programs use TCP for their transport protocol. As they are stripped down, the server can only serve one client at a time. That's because, in effect, serving client #1 absorbs all the server's attention so none it left to take care of an incoming client #2 that may show up. Real-world servers want to be able to serve a client, then have "hands free" to accept a second, third, fourth one, and have them all served concurrently. They achieve that by remaining devoted full time to incoming clients, never serving any of them. For that, they spawn dedicated server copies, one per client. Each server copy has only one client to take care of. Like this:
Note there are 3 servers, all in the upper center. They are different from one another, and the same as one another. They are different in that they are separate, distinct processes. They are the same in that they are all the same program, they all are running identical code. However, the "listening server" is doing different things than the "server child" instances, because that code contains a central if/else in which the listener and the children take opposite branches. The children are the ones who perform the actions that distinguish this particular server (e.g., if it's a file transfer server they are the ones that transfer the files, the listener does not).
The pseudo-coded structure of a non-concurrent or iterative server like client3.c is shown below, contrasted with one that concurrently would manufacture a dedicated copy of itself whenever a new client asked for service:

I provide an adapted, concurrent version of server3.c called server3-concurrent.c. (It does not come with any specially adapted client, since the regular client3.c is suitable for it.)
the exercise to perform
You will do this exercise in a single linux machine, running both a client and two servers in that machine.
|
Note: there is no conflict in that. When two programs interact as client and server, the requirement is the the client must run on a machine, the server must also run on a machine, and they must interact through the network stack software. Your machine is a machine so satisfies both client's and servers's locus requirement. And the stack's loopback interface provides boomerang from/to connectivity between a machine and itself. |
A client program that wishes to contact its server needs to know an IP address of the machine where the server runs, and the port number by which the server is identified within its machine. These programs hard code that information. As coded, client3 uses the self-referential IP address of the machine where it itself runs (127.0.0.1). That means you have to run the servers on the same machine as the client. And for port number all use 2910 (arbitrarily). Later in the client, for experimentation, you could edit the IP address (and move the servers to it) and/or the port number (and conform the servers' code to it). But here we will run both client and servers together on the same machine.
Log in to the machine as student, launch the graphical desktop ("startx" command), from which launch a terminal window (icon under "Activities" menu), in which become root ("sudo su -" command). Make a subdirectory within your home directory:
cd
mkdir concurrentserver
cd concurrentserver
In that directory obtain and place file programs-my-adapted-letter-upgraders.tar. It is a tar file, similar to a zip file. Deploy source code for two servers and their client:
tar -xzvf programs-my-adapted-letter-upgraders.tar.gz ./server3.c ./server3-concurrent.c ./client3.c
server3 is the regular, so-called iterative server. server3-concurrent is its concurrent version. client3 is the client for both of them. Compile the programs:
gcc server3.c -o server3
gcc server3-concurrent.c -o server3-concurrent
gcc client3.c -o client3
It will be useful to run things in multiple windows:
terminator -f &
Split the window horizontally (right-click drop-down menu option, or ctrl-shift-O keystroke). You can shift focus between windows by clicking on the one you want, or ctrl-tab keystroke. With focus on the lower window, split it horizontally. Now you have three windows to work with.
Now let's run the client against each server. Do it in the upper window:
./server3 &
Press the enter key a couple times. The server is running in the background ("&" did that). Though not prominent it's up, running, and ready for contact from a client. So:
./client3
The letter that client3.c is hard coded to send is R, so the server returns S and the client says so on screen. Now replace the iterative server with the concurrent one and play the client off against that one:
killall server3
./server3-concurrent &
./client3
The experience is identical. What was delivered and returned is the same in both cases. What is different isn't visible.
Here is what's different:

To understand it you need to know about about process creation, specifically about the operating system's fork( ) function which is the process creator. You can listen to a description here.
Let's observe operationally. We will run the concurrent server (in the background) and the client from within the upper window. We will use the middle window for netstat monitoring and the lower window for ps (process listing) monitoring.
In the middle window:
watch -n 1 'netstat -pant | grep -E "client|server"'
In the lower window:
watch -n 1 "ps -ef | head -n 1; ps -ef | grep server3 | grep -v grep"
In the upper window:
./server3-concurrent &
When the server runs, netstat in the middle window shows it to be listening on port 2910, as it is coded to do. The lower window shows it to be running as a process and gives its PID (process id) and its parent's pid (PPID).
In the upper window:
./client3
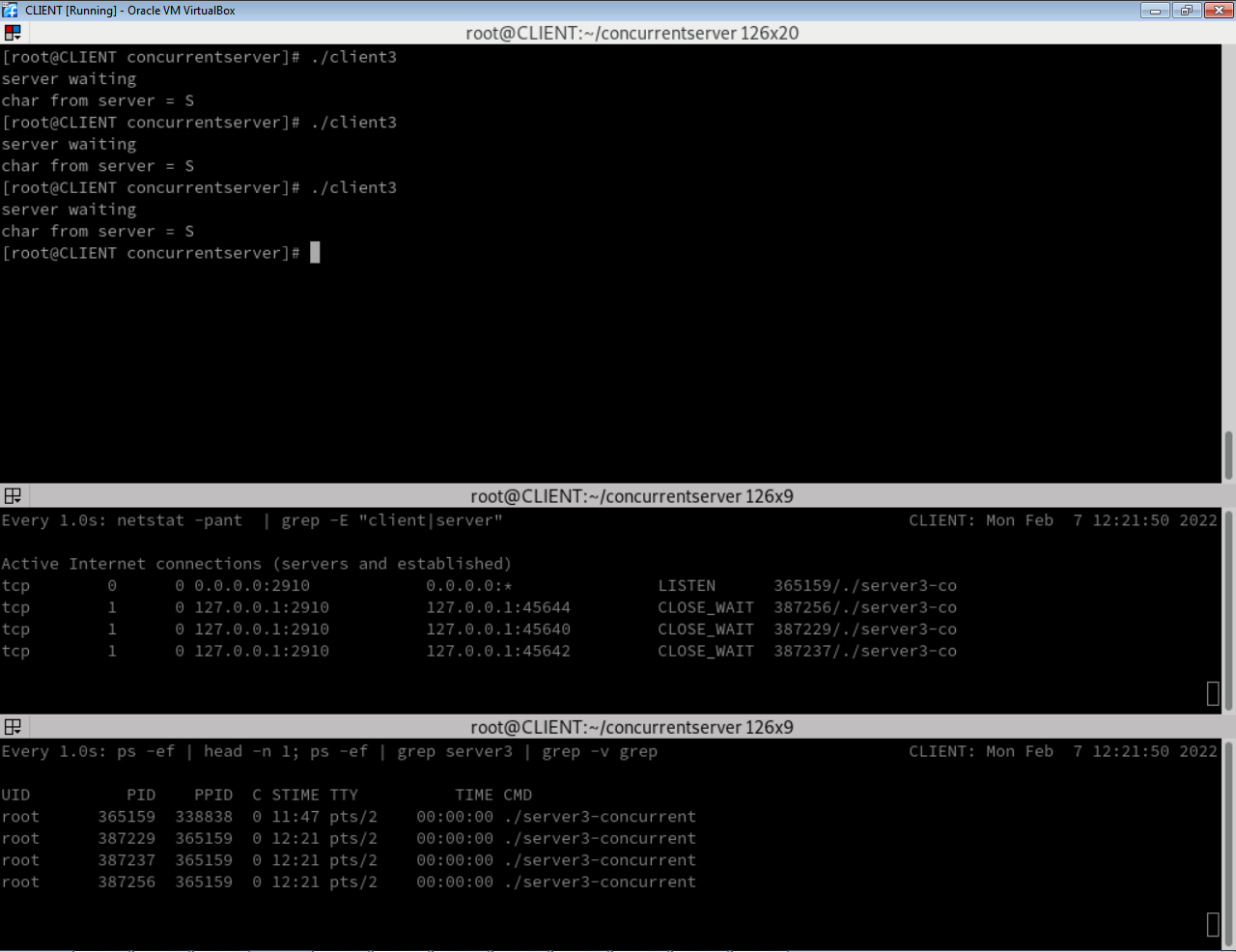
The client exchanges its R for an S from the server and terminates. As for the server(s), the lower window shows server3-concurrent a second time. But look at the process id numbers. The second process shown is a different one from the original, though they may be the same in name. Name only! the second one is the result of the first one's having executed its fork( ) function call, in line 37. The second one is the first one's child (note that the child's PPID matches the parent's PID). As such it has performed the application logic (conditionally reserved for child copies of this code) and thus returned S to the client, which has now already terminated. The only reason this second server hasn't terminated yet is that it delays for 30 seconds in line 43. After that it will terminate and disappear. Identify the second server in the middle netstat window; you can pinpoint it by its PID. Note that while the parent remains in a "LISTEN" state (that's the point), the child isn't listening it's in "CLOSE_WAIT" state. These "states" are creatures of tcp. They belong to tcp. udp for example doesn't have them. Now in the upper window run the client 3 times in succession:
./client3
./client3
./client3
Study the screen output. The parent has a lot of kids, and it keeps listening the whole time. The kids (as usual) don't listen. That's not their job. They go and handle clients, one kid server per client. And the parent doesn't process client requests-- that's not its job-- but only listens for them at all times and delegates to kids.
For this particular server, operating concurrently doesn't gain much. But in those that may have long-duration application logic plus many client requests, this technique means no client need stand in line behind another that arrived first, or be refused. This is like your experience at store checkout with too many customers and too few employees manning the cashier lanes. You have to bunch up with other customers and wait in line behind them. When the manager calls "all hands on deck" and activates enough cashier lanes, there can be one cashier per individual customer, obviating lines and client wait time.
Some applications, like this one, wait until arrival of client requests and spawn server kids only then, dynamically. Others expect a lot of client business and set up children ahead of time in anticipation. Apache does that. Run and observe it:
systemctl start httpd
ps -ef | grep [h]ttpd
You launched only one copy of httpd (apache). How many do you see? Whose children are they? Are they busy serving browser clients right now? What time savings do they accomplish when a client request arrives?
What to turn in:
Turn in a screenhot taken at the point above after you run 3 successive client processes. Take the screenshot within 30 seconds, before the timeouts expire and the processes terminate. Name the file "concurrent-server-screenshot.jpg" (or .png). Mine looks like this.
{kind=link}